As organizations begin deploying AI agents across more business processes, most of the conversation focuses on intelligence. We talk about reasoning, planning, tool use, context windows, and autonomous workflows. The assumption is that if we make agents smart enough, they will naturally become more useful.
But intelligence is only part of the equation. The real challenge starts after an agent delivers its answer.
What happens to the knowledge generated during that interaction? What happens to the feedback provided by users? What happens to the decisions, corrections, exceptions, and lessons learned over time?
In most systems, the answer is simple: nothing. The interaction ends, and the knowledge disappears.
Organizations Do Not Run on Intelligence Alone
Human organizations have never relied solely on individual intelligence. Even the most experienced employees cannot remember every decision, every exception, every lesson learned, or every piece of context accumulated over years of operation.
That is why organizations build documentation.
We create wikis, playbooks, postmortems, decision logs, knowledge bases, and operating procedures. These systems allow knowledge to persist beyond a single conversation or project. More importantly, they allow knowledge to become shared rather than remaining trapped inside individual people.
When viewed through this lens, modern AI systems reveal an interesting limitation.
Many agents are excellent at generating answers, but surprisingly poor at creating institutional memory. They can analyze data, detect patterns, and explain findings, yet they often treat every interaction as an isolated event. The system may have access to historical information, but it rarely captures the outcomes of previous interactions in a way that continuously enriches future decisions.
This creates a gap between intelligence and learning.
The Missing Layer in Agentic AI
As AI agents become more deeply integrated into business workflows, organizations need more than a history of conversations.
They need a structured way to capture and organize what agents discover.
Imagine an agent investigating an unusual business event. It analyzes data, identifies potential causes, and presents a conclusion. A user reviews the result and explains that the event was actually caused by a planned campaign. The explanation is valuable because it provides context that the data alone could not reveal.
Today, that knowledge is often lost.
Tomorrow, the same situation may occur again, forcing both the user and the system to repeat the same reasoning process.
A more effective approach is to treat every significant interaction as a knowledge asset. The original question, the analysis, the user feedback, and the final decision become connected pieces of information that can be revisited and reused in the future.
Over time, these individual fragments begin to form something larger than conversation history. They become a living knowledge system.
From Documents to Living Knowledge
This is where the concept of an LLM Wiki becomes interesting.
Traditional wikis are designed around documents. Pages are created manually, linked manually, and maintained manually. They are valuable, but they often struggle to keep pace with how quickly modern organizations generate information.
AI systems create an opportunity to rethink that model.
Instead of asking people to continuously document everything, agents can automatically generate and maintain knowledge artifacts as part of their normal operation. Questions become pages. Decisions become pages. Feedback becomes pages. Summaries become pages. Relationships between them are created automatically.
The result is not simply a collection of documents. It is a continuously evolving representation of organizational knowledge.
More importantly, it captures not only outcomes but also context.
A future user can understand what happened, why it happened, who provided feedback, what lessons were learned, and how those lessons influenced future decisions.
That context is often more valuable than the answer itself.
Why Knowledge Graphs Matter
Once knowledge is represented as connected entities rather than isolated documents, visualization becomes much more powerful.
A traditional wiki encourages users to search for information they already know exists. A knowledge graph encourages exploration.
Instead of reading a single page, users can navigate relationships between events, decisions, feedback, summaries, and policies. They can move from a high-level overview to the details of a specific decision. They can trace how a particular insight influenced future actions across the organization.
At first, that graph can look messy because real organizational knowledge is messy. Exceptions, lessons, decisions, and feedback do not arrive in clean categories. The value is that the graph makes those relationships visible enough to inspect, refine, and reuse.
The graph is not the destination.
It is the interface that allows people to understand how knowledge evolves over time.
This distinction is important because the ultimate goal is not visualization for its own sake. The goal is to make organizational learning visible.
The Future of Organizational Memory
For years, enterprise software has focused on storing information. AI is pushing us toward a different objective: capturing understanding.
The most valuable AI systems of the future may not be those that generate the most sophisticated answers. They may be the systems that do the best job of preserving and organizing collective knowledge.
In that world, AI agents become more than assistants. They become contributors to an evolving organizational wiki that grows with every interaction, every decision, and every lesson learned.
Perhaps the next major breakthrough in AI will not come from larger models or more powerful reasoning.
It will come from giving AI something organizations have relied on for decades: a place to remember.
Harness Engineering: What We Learned Building Agentic AI
05.13.2026
Agentic AI Is Not Just About Prompts
A lot of the conversation around Agentic AI still revolves around prompts — how to structure instructions, improve reasoning, or get more reliable outputs from large language models. Prompt engineering is important, but while building our own solution, we quickly realized that it is only a very small part of what makes AI usable in real production environments.
The real challenge starts when AI stops being a demo and becomes part of an actual operational workflow.
At that point, the focus shifts away from "how do we get better responses from the model?" and toward a much bigger question: how do we build systems around the model that are reliable, observable, debuggable, and safe to operate?
That is where harness engineering becomes far more important than prompt engineering.
From AI Features to AI Systems
One of the most important architectural decisions we made was understanding that the LLM should not replace deterministic systems. Instead, it should sit above them as a coordination and decision-making layer.
In practice, this means the model is responsible for understanding intent, planning workflows, coordinating tools, and translating outputs into business context. The actual analytical logic, calculations, validations, and domain-specific processing still happen inside traditional backend systems.
This separation turned out to be critical.
It allowed us to preserve predictability and control while still benefiting from the flexibility of natural language interfaces and agent-based workflows. Rather than creating "AI that does everything," we ended up building systems where AI orchestrates existing infrastructure in a more intelligent and adaptive way.
That distinction may sound subtle, but it fundamentally changes how production AI systems should be designed.
Most of the Work Happens Around the Model
One of the more surprising realizations during development was that most engineering effort had very little to do with the model itself.
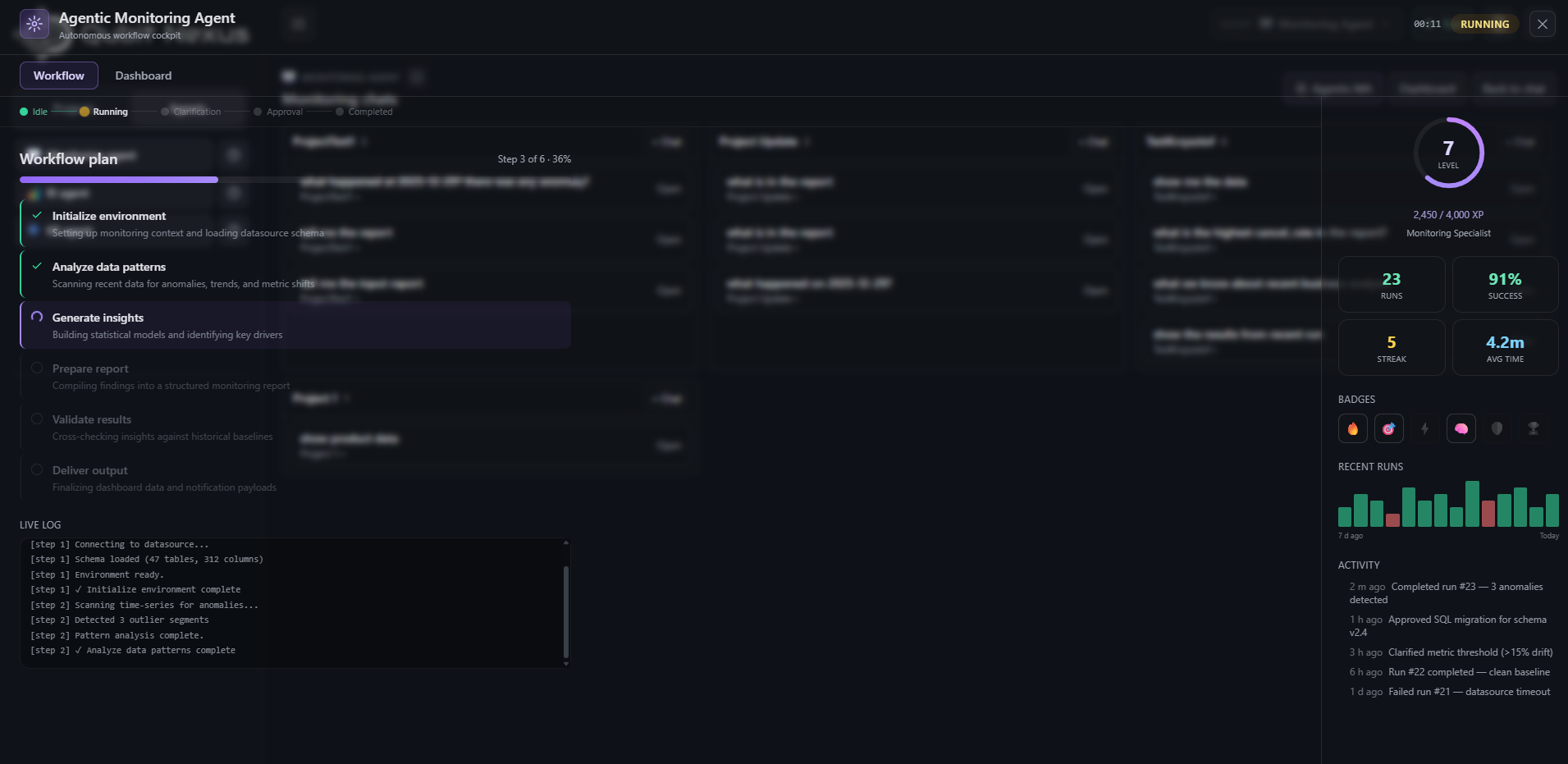
The majority of complexity appeared in the surrounding infrastructure: managing workflow state, validating inputs, handling retries, coordinating execution, tracking failures, storing artifacts, exposing status updates, and making every step observable and reproducible.
In theory, an AI agent can look impressive after a few carefully designed prompts. In production, however, the problems are much more operational.
What happens when a workflow partially fails?
How do you reproduce an execution path?
How do you validate tool usage?
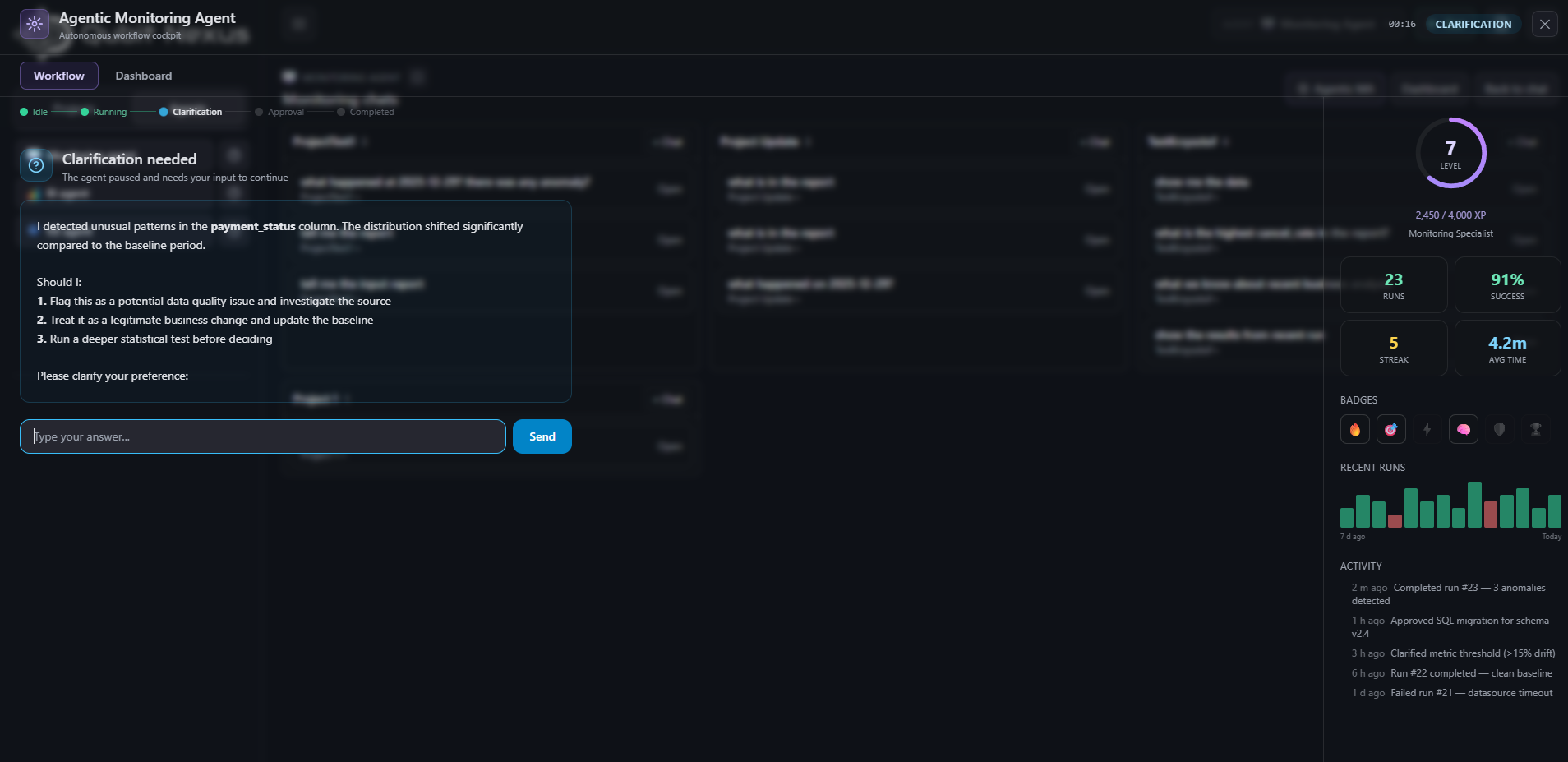
How do you pause a process for human approval?
How do you debug a multi-step run that involved several tools and intermediate decisions?
Those questions have much less to do with prompting and much more to do with systems engineering.
That is ultimately what harness engineering represents: the operational layer that makes Agentic AI trustworthy.
Why Observability Changes Everything
As workflows become more autonomous, observability becomes one of the most important capabilities in the entire architecture.
Traditional applications can often operate with relatively simple logging and monitoring. Agentic systems are different because they involve reasoning steps, orchestration, intermediate decisions, and tool interactions that evolve dynamically during execution.
Once AI starts coordinating workflows, teams need visibility into the entire decision process. They need to understand what the original objective was, how the plan evolved, which tools were called, what failed, and why the system produced a particular outcome.
Without that level of visibility, it becomes extremely difficult to trust AI systems operationally.
In many ways, observability becomes the foundation that allows organizations to move from AI experimentation to AI adoption.
The Emergence of Organizational Memory
Another interesting direction that emerged during development was the idea of structured memory and retrieval.
The real value of Agentic AI does not come from generating isolated responses. It starts appearing when systems can accumulate operational context over time and reuse previous outcomes as part of future decision-making.
That creates the possibility of building organizational memory around workflows, approvals, feedback, and historical patterns.
Over time, AI systems become capable not only of executing tasks, but also of learning how an organization operates — which approaches worked well previously, which configurations created problems, and which decisions were ultimately accepted by humans.
This feels like one of the most important long-term shifts in enterprise AI: moving from stateless interactions toward systems that continuously accumulate operational knowledge.
The Biggest Lesson
The biggest takeaway for us was ultimately very simple.
The value of Agentic AI is not created when a model generates impressive text. The value appears when AI can safely participate in real operational processes.
And making that possible requires much more than prompts.
It requires architecture, orchestration, observability, memory, governance, and carefully designed integration with deterministic systems.
That is what turns AI from a feature into infrastructure.
Cognitive Cartography: A Better Way to Explain the AI Black Box
03.26.2026
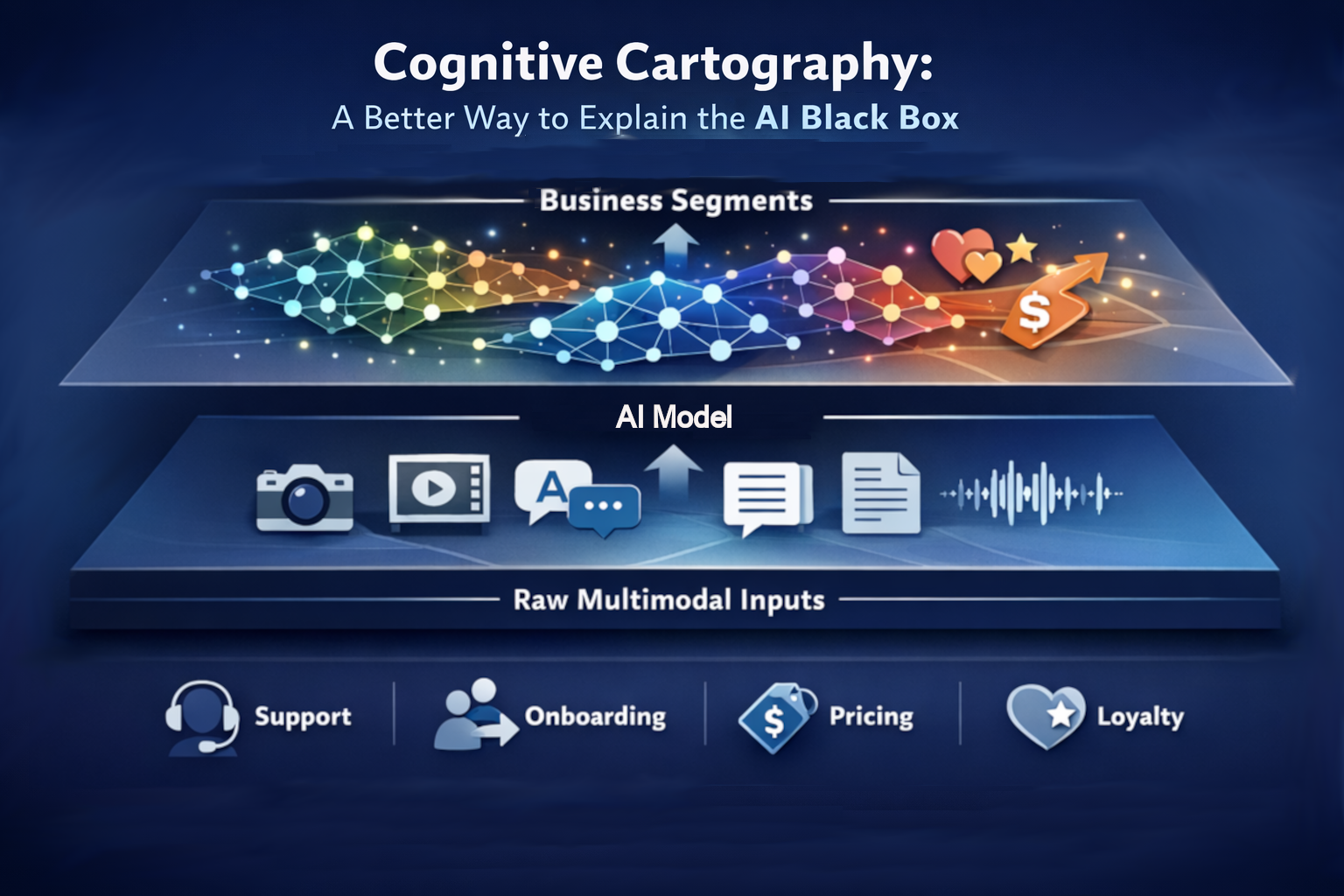
As AI systems become more multimodal, more powerful, and more embedded in business decisions, one question keeps getting louder: how do we make these models make sense? Not just to data scientists, but to business leaders, CX teams, and domain experts who need to trust the output, challenge it, and act on it. That is why cognitive cartography is so compelling. It offers a way to move beyond the black box by making AI’s internal understanding visible, navigable, and explainable through examples.
From feature engineering to human-centered understanding
Traditional feature engineering was built to help machines. It transforms raw data into model-friendly inputs that improve prediction, often by compressing complexity into abstract variables. That works well when the goal is accuracy alone. But in a world of human-AI collaboration, accuracy is not enough. Business users need to understand how information clusters, how concepts relate, and why the model arrived at a conclusion. Cognitive cartography extends the logic of feature engineering into something more human-centered: instead of only asking how to optimize data for the model, it asks how to organize information so people can navigate it, interpret it, and reason with it.
This matters even more now because business questions rarely live in one clean data set. The real challenge in analytics is connecting distinct domains: customer conversations, emails, transactions, product usage, documents, images, pricing decisions, team workflows, and external signals. Foundation models can help bridge those domains, but only if the result is understandable. For many business contexts, hallucination is not acceptable. Leaders do not just want an answer; they want supporting examples, adjacent evidence, and a way to inspect the logic behind the answer. Cognitive cartography helps by turning latent AI representations into visual, layered landscapes that people can actually explore.
Why representation learning makes this possible
At the heart of modern AI is representation learning: models learn meaning by building hierarchies from simple signals to more abstract concepts. In images, that might start with edges and textures, then shapes, then objects, then scenes. In language, words with similar meanings end up near one another in embedding space, and sentences with related ideas cluster together. The same principle can extend across multimodal data, where text, structured business records, images, graphs, or even scientific data can be mapped into a shared conceptual space.
Cognitive cartography makes that invisible structure visible. At the lowest layer, the model estimates concepts and relationships. As you move upward, those concepts are grouped into broader patterns. At the top, business users can work with intelligible segments: clusters they can label, rename, compare, question, and refine. That is the real breakthrough. Instead of forcing all intelligence through a chatbot interface, we give people a map of how the system understands the domain. Users can inspect clusters, ask what makes one segment different from another, request examples, and redefine labels in ways that align with business reality. Those human-defined labels can then become high-value training data for fine-tuning or specializing models.
A practical example: customer journey mapping in CX
This is especially powerful in customer experience. Customer journeys are rarely linear, and they are almost never captured in a single source. The real journey lives across survey comments, service tickets, call transcripts, clickstream behavior, product usage, complaints, purchase history, and even agent notes. A foundation model can detect patterns across all of that, but without a transparent structure, the insights remain hard to trust and harder to operationalize.
Now imagine applying cognitive cartography to that journey. At the lower levels, AI identifies fine-grained concepts such as friction during onboarding, confusion around pricing, repeated contact for the same issue, urgency signals, or signs of loyalty risk. At higher levels, those concepts can be grouped into larger segments such as “customers struggling to get started,” “high-value customers experiencing service breakdown,” or “price-sensitive customers seeking reassurance.” At the top layer, a CX leader can inspect those segments directly, relabel them, merge or split them, and ask for representative examples from each group. That creates a deterministic, evidence-based view of the journey—one that is far more actionable than a generic summary. It also creates labeled knowledge that can be reused to train better specialized models for future decisions.
Why visual AI matters now
This is why visual AI is not just a nice interface layer. It is becoming essential infrastructure for trustworthy business AI. When people can see how information is organized, how clusters form, how concepts evolve over time, and how different parts of the business connect, they are far more able to work with AI rather than simply consume it. The deck’s reference to the Mantis visual data science approach is a strong example of this direction: giving users the ability to compare clusters, inspect distances, summarize groups, and explore differences interactively. That kind of transparency helps put humans back in the middle of the system, where they belong.
Cognitive cartography will not eliminate the complexity of modern AI. But it gives us a much better way to live with that complexity: by exposing the conceptual layers beneath the model, grounding answers in examples, and allowing business users to shape the labels and segments that matter most. In a world where AI systems are growing more powerful and more opaque at the same time, that may be one of the most important capabilities we can build.
Beyond the API: How QubitNexus Customizes AI Systems That Actually Work
02.26.2026
Almost every company can access powerful models through an API today. That’s no longer the differentiator.
What does differentiate is whether you can turn that raw capability into a reliable, cost-aware, and operationally safe system that fits a real business workflow—one that people can trust day after day.
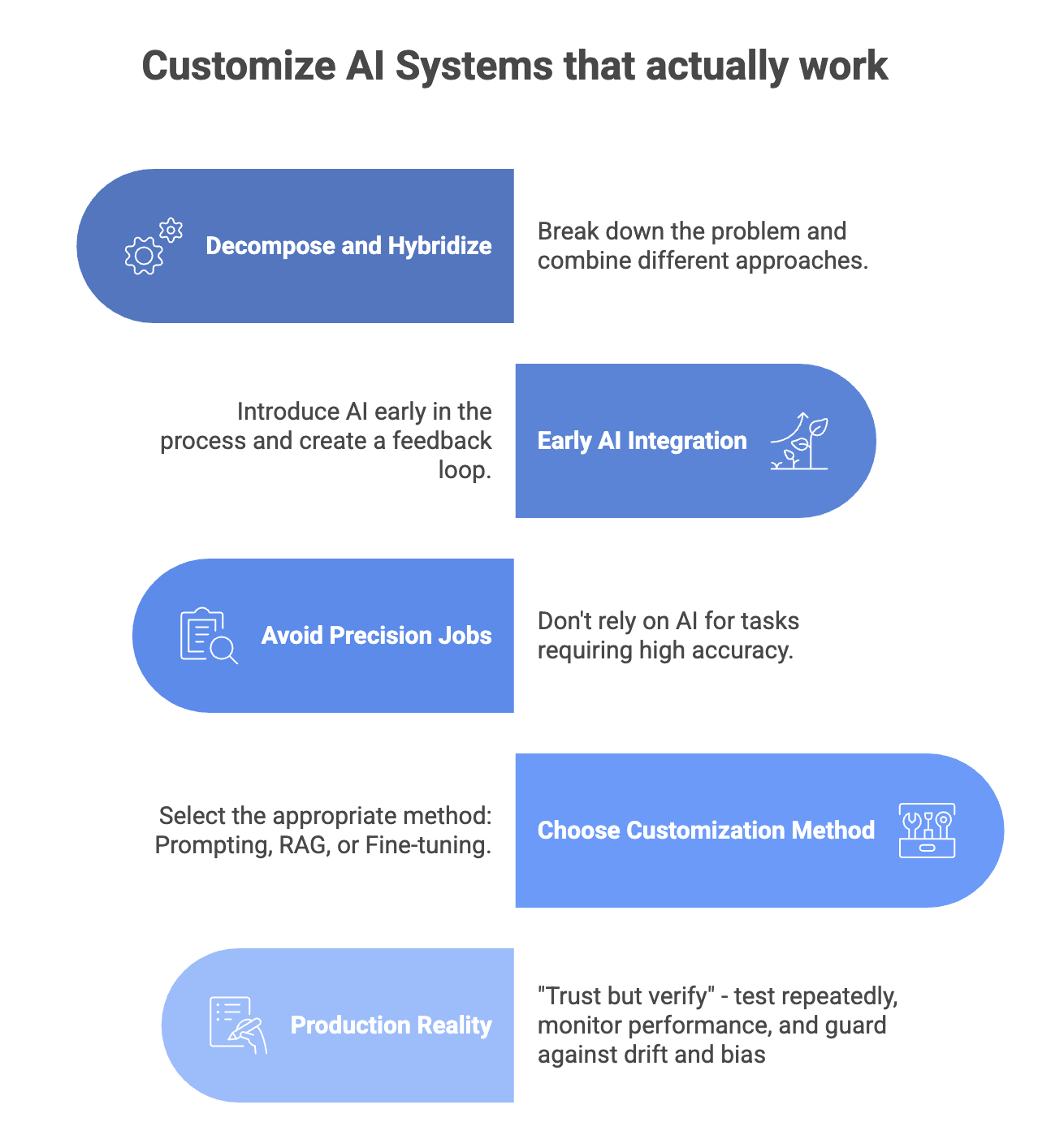
At QubitNexus, we’ve found that “AI customization” isn’t primarily about picking a model. It’s about engineering the right system around the model: decomposing the problem, placing AI where it adds leverage, and pairing it with deterministic pipelines, validation, and human review where precision matters.
Here’s our practical playbook.
1) Start with the simplest thing that works
Before reaching for RAG, fine-tuning, or “agent” orchestration, we always start by proving a baseline:
Can a strong off-the-shelf model do the task well enough with a clean prompt?
Can we get stable results with structured formatting?
Do we understand the failure modes on real examples from your business?
This “keep it simple” approach prevents overengineering and gives you clarity about what customization is actually required—if any.
2) The #1 best practice: Decompose the problem and hybridize the solution
If you’re building an AI solution end-to-end, the fastest way to get burned is to treat the model as the whole system.
Instead, we recommend treating AI as one component inside a workflow, and decomposing the problem into smaller subtasks. Then assign each subtask to the best tool. This hybrid approach is how you get reliability without losing the acceleration benefits:
Deterministic / traditional systems: handle the “hard guarantees” parts: data pipelines, rules, calculations, validation, and audit-ready monitoring.
AI systems: handle the “language + judgment” parts: drafting and summarizing, extracting structure from text, routing and classifying, translating formats, and explaining outcomes.
3) Put the AI early, not late (and build the “catch + correct” loop)
A principle we use constantly:
Use GenAI earlier in the workflow to create candidate structure or drafts, then validate downstream with deterministic checks and/or human review.
If AI hallucinates late in the process, it can contaminate downstream systems and become hard to detect.
If AI produces an early draft or extraction, you can validate and correct it, request a retry or route to human review.
A practical “catch and correct” pattern
AI generates a candidate output (draft, extraction, classification)
Deterministic validators check formatting, completeness, and business constraints
Grounding checks confirm that claims match known data (or retrieved sources)
Human-in-the-loop review for high-risk cases
Logging + feedback captured for iteration
This is how you ship GenAI responsibly in real operations.
4) Don’t ask GenAI to do “precision-required” jobs end-to-end
In many deployments, teams can quickly reach something like 80% performance with basic prompting. With better structure and examples, they can often reach 90–95%.
But the “last 5%” is where projects stall—especially when the task requires strict correctness, like converting between formal structures (policy → logic → code), or generating outputs that go directly into automated decision systems.
When near-perfect accuracy is required, we rarely recommend forcing the model to do the full transformation by itself. We redesign the workflow:
break the task into smaller steps,
use deterministic components where correctness is non-negotiable,
and keep AI on the parts where approximation is acceptable and reviewable.
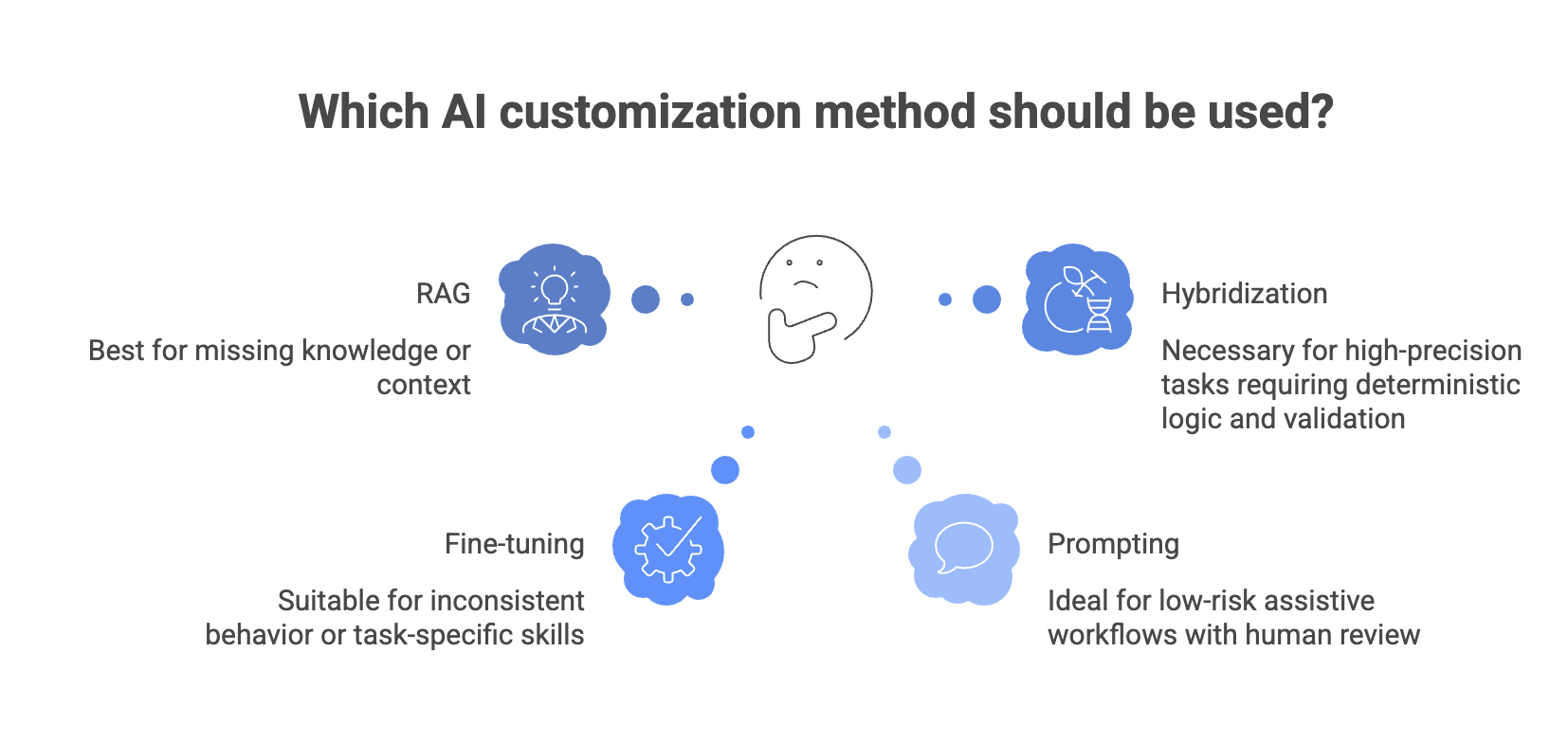
5) Choosing the right customization method: Prompting vs RAG vs Fine-tuning
Most GenAI customization falls into three approaches. Each is useful—but for different reasons.
6) A simple decision guide we use with clients
When deciding how to customize, we ask:
7) Production reality: “Trust but verify”
No matter which approach you pick, production GenAI requires discipline:
Run the same prompt many times and measure variability
Build a representative test set of real cases and edge cases
Audit trail: log sources used + final message + reviewer decisions
This structure avoids hallucination becoming customer-facing truth—and makes performance measurable.
The QubitNexus takeaway
Custom GenAI isn’t magic, and it isn’t just “connect an API.” It’s a system design problem:
decompose the workflow,
use deterministic pipelines wherever precision is required,
place AI early and validate downstream,
and choose prompting vs RAG vs fine-tuning based on what you’re really missing (context vs behavior vs scale).
That’s how you get real business impact without getting burned.
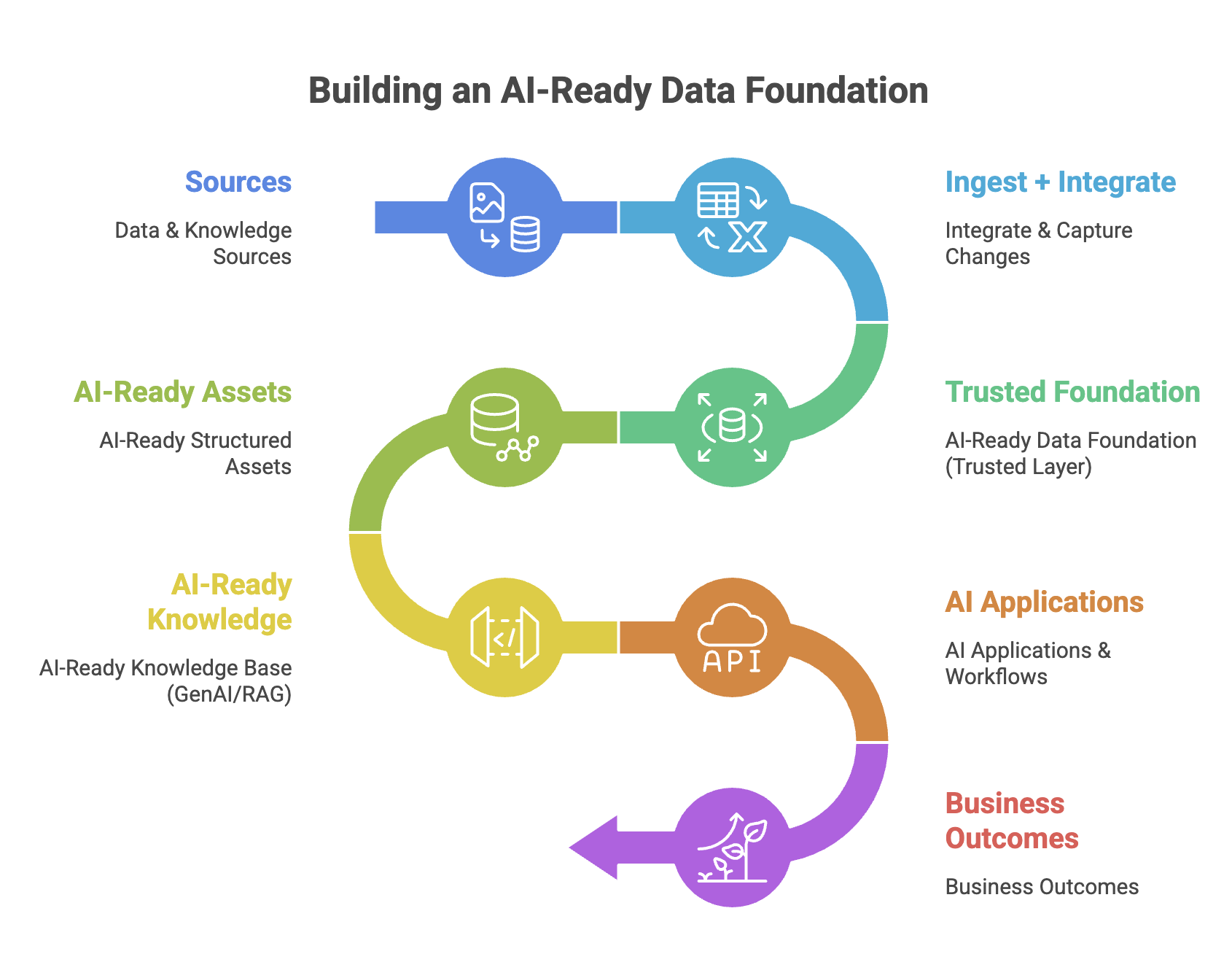
AI-Ready Data Engineering: Building Foundations That Don’t Break in Production
02.05.2026
AI isn’t blocked by a lack of models anymore. It’s blocked by data foundations that were designed for dashboards, not decisions. As AI becomes part of how work gets done—approving exceptions, prioritizing customers, routing cases, forecasting risk, drafting responses, and increasingly acting through agentic workflows—the definition of “good data engineering” changes.
Traditional data engineering optimized for reporting: consolidate data, model it once, and refresh it on a schedule. AI engineering needs something different: context-rich, governed, and reliable data that stays trustworthy at inference time—even as sources change, policies evolve, and the business redefines what success means.
At QubitNexus, we call this shift AI-ready data foundations: centralized, integrated, and designed to support production AI—predictive models, GenAI/RAG, and agentic workflows—without turning operations into a guessing game. This post explains what changes, what to build, and our strategy for getting there.
Why AI forces a rethink of data design
For years, most data stacks were built with a simple goal: help humans make sense of the business. We built pipelines to consolidate sources, cleaned them up enough to report on, and shipped dashboards that people learned to interpret with context and judgment.
AI flips that model. Instead of data informing a human decision, data increasingly becomes the decision—powering recommendations, automating routing, predicting risk, and generating responses that move work forward.
When data is used that way, the old tolerance for “close enough” disappears. Inconsistent definitions stop being annoying and start becoming dangerous. Quiet schema changes, stale signals, and undocumented workarounds don’t just distort a metric—they can change what the AI does in production.
That’s why AI forces a rethink of data design: the foundation has to carry meaning, governance, and reliability as first-class requirements. In practice, “good data for AI” is less about volume and more about context, control, and confidence—built into the system from the start.
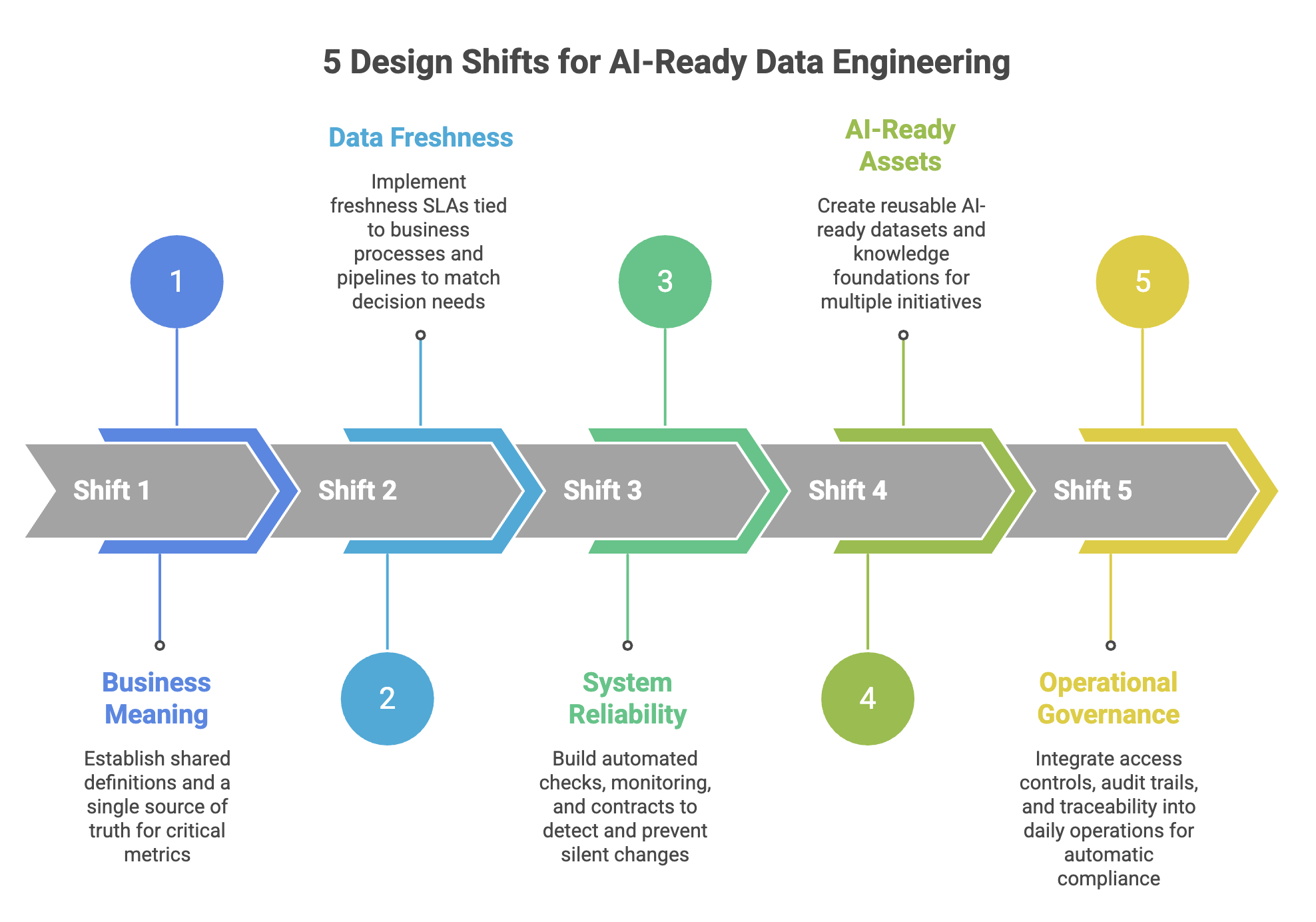
The 5 design shifts of AI-ready data engineering
Each shift reframes what “good” looks like for data in production AI. Together, they mark the move from descriptive analytics to trustworthy AI outcomes.
From “data availability” to business meaning everyone agrees on.
AI can’t succeed if the organization can’t answer basic questions consistently. Shared definitions for critical metrics and entities become the single source of truth for how results are calculated—cutting conflicting numbers and raising trust in AI outputs.
From “daily refresh” to data freshness that matches the decision.
Not every workflow needs real-time, but fraud, staffing, collections, or customer escalations often do. We tie freshness SLAs directly to the business process so AI recommendations stay relevant.
From “pipelines that run” to systems that stay reliable when things change.
Silent schema changes or late feeds break AI behavior without tripping alerts. Automated checks, monitoring, and data contracts detect upstream issues early so they don’t become business incidents.
From “reporting data” to AI-ready assets.
Predictive and GenAI systems need curated training sets, trustworthy features, and governed knowledge bases. Reusable AI-ready assets prevent teams from rebuilding prep work for every use case.
From “governance as a project” to governance built into daily operations.
With GenAI and agents, leaders must answer: Where did that output come from? Who touched the data? Built-in access controls, audit trails, and traceability make compliance automatic instead of heroic.
The QubitNexus strategy: AI-ready data foundations
We don’t start with tools or architecture. We start with the business decisions AI is expected to improve—and build the foundation that makes those decisions reliable in production.
Align on the AI outcomes that matter. Identify the highest-value AI use cases, define success metrics, map workflows, and surface trust gaps like inconsistent definitions or latency issues. Outcome: a prioritized roadmap tied to business impact—without boiling the ocean.
Build a shared foundation that multiple AI use cases can reuse. Instead of one-off pipelines, we construct centralized, AI-ready foundations: consistent definitions, reliable integrations, high-confidence data/knowledge sources, and embedded governance. Outcome: faster delivery of new AI capabilities with less rework.
Operationalize trust: quality, monitoring, and auditability. Put mechanisms in place to keep AI reliable as systems evolve—early issue detection, traceability from outputs back to sources, and scalable access controls. Outcome: leadership can trust AI in production because it’s explainable, monitorable, and governable.
The Building Blocks Behind Reliable AI
AI failures rarely come from the model—they come from what the model is fed. The goal of an AI-ready data foundation is to ensure the inputs are accurate, current, explainable, and compliant, whether the AI is predicting risk, powering a GenAI assistant, or automating a workflow. Here’s the simple blueprint we use to connect your sources to AI outcomes without introducing fragility.
AI is only as reliable as the foundation beneath it. If you want AI that scales, you need data that’s consistent, current, governed, and explainable—by design. That’s what we build at QubitNexus: AI-ready data foundations that make AI work in production.
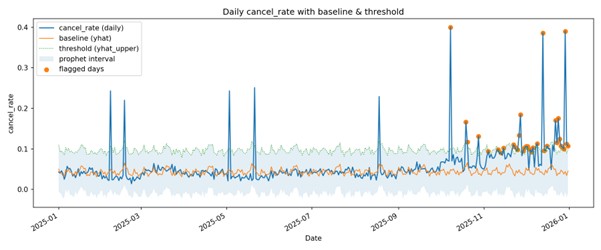
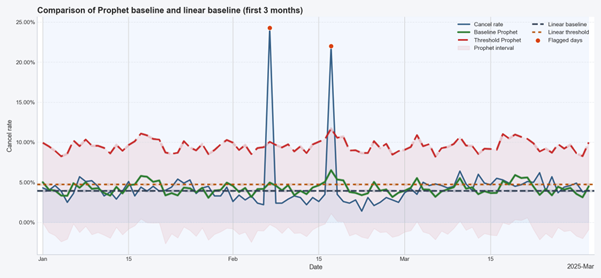
Prophet: ~3X fewer false alerts after adding a forecasting layer to our custom AI agent for anomaly detection.
01.19.2026
Scalable AI Agents you can trust
The Additive Structure Behind Prophet
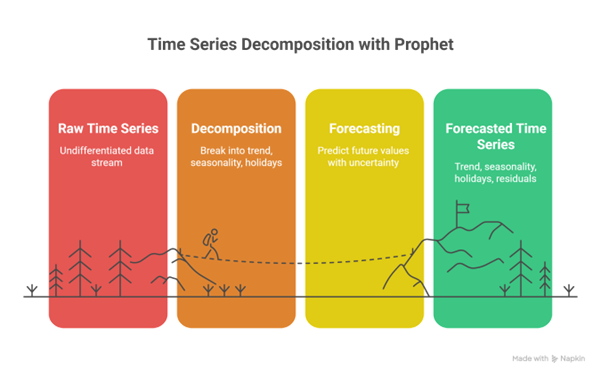
Time-series forecasting often feels harder than it should be. Real-world data is messy: trends shift, seasonality changes, holidays distort patterns, and gaps or outliers are common. Prophet was designed with exactly this reality in mind, offering a pragmatic model that balances statistical rigor with usability.
At a high level, Prophet assumes that any time series can be decomposed into a small number of interpretable components:
y(t) = g(t) + s(t) + h(t) + ε
This structure is not just convenient—it reflects how many real processes behave. Long-term growth or decline is captured by the trend component g(t). Repeating patterns such as weekly or yearly cycles are handled by the seasonal term s(t). Known, external disruptions (like holidays, promotions, or system changes) can be explicitly modeled through h(t), while ε accounts for random noise.
Because each part is modeled separately, Prophet makes it easy to reason about forecasts and diagnose where changes in the data are coming from.
How Trend Modeling Works in Theory
The trend component is where Prophet does much of its heavy lifting. Rather than fitting a single global trend, Prophet models growth as a piecewise function—typically linear or logistic. The model automatically places changepoints along the timeline where the growth rate is allowed to shift.
From a theoretical perspective, this approximates non-stationary behavior without explicitly differencing the data. Regularization plays a key role: while many potential changepoints are considered, a prior discourages large or frequent changes unless the data strongly supports them. This Bayesian regularization helps prevent overfitting and keeps the trend smooth and interpretable.
Seasonality as a Flexible Basis Expansion
Seasonality in Prophet is modeled using Fourier series, which provide a compact and flexible way to represent periodic patterns. Instead of assuming a fixed shape for seasonality, Prophet learns a combination of sine and cosine terms that best fit the data.
Theoretically, this can be viewed as projecting the time series onto a set of periodic basis functions. The result is a smooth seasonal component that can capture complex but stable cycles.
Depending on the data, this component can be added directly to the trend (additive seasonality) or scaled by it (multiplicative seasonality), allowing seasonal effects to grow or shrink with the level of the series.
A Bayesian Framing and Uncertainty
Although Prophet feels like a deterministic tool, it is grounded in a Bayesian framework. Priors are placed on key parameters such as trend changes and seasonal coefficients, and forecasts are generated by sampling from the posterior distribution.
This enables Prophet to produce uncertainty intervals rather than just point estimates. These intervals reflect both observation noise and uncertainty in the model parameters, which is especially useful for anomaly detection where deviations outside the confidence range are meaningful.
Why This Theory Matters in Practice
What makes Prophet compelling is how this theoretical foundation translates into practical benefits. The additive structure keeps the model interpretable. Piecewise trends handle structural changes gracefully. Fourier-based seasonality captures recurring patterns without manual feature engineering. And the Bayesian framing provides uncertainty estimates that support better decision-making.
Just as importantly, Prophet is forgiving. It handles missing data and outliers reasonably well without heavy preprocessing, reducing the time spent cleaning data before you can get insights.
Simple Knobs, Real Leverage
Prophet’s design philosophy favors a small number of meaningful tuning parameters. Adjusting the interval width or the changepoint prior can significantly change model behavior without requiring deep expertise in time-series theory.
In short, Prophet shines not because it’s the most complex model, but because it’s transparent, robust, and practical—qualities that matter when forecasting real-world data.
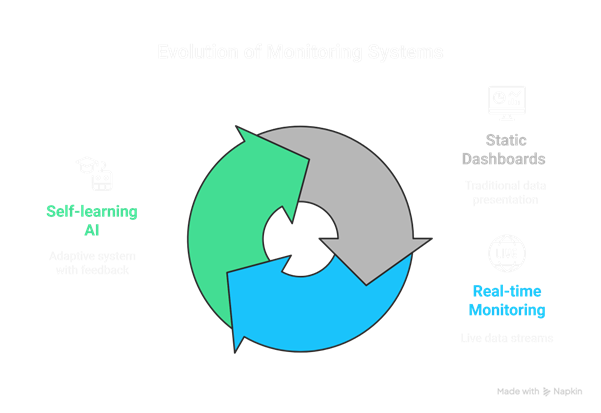
From Dashboards to Self-Learning Insights: The Next Evolution in AI Monitoring
11.12.2025
Why We Built It
Most companies only spot churn when it’s already visible in monthly dashboards — and by that time, the damage is done. Teams scramble to diagnose what happened, armed with fragmented data and incomplete context.
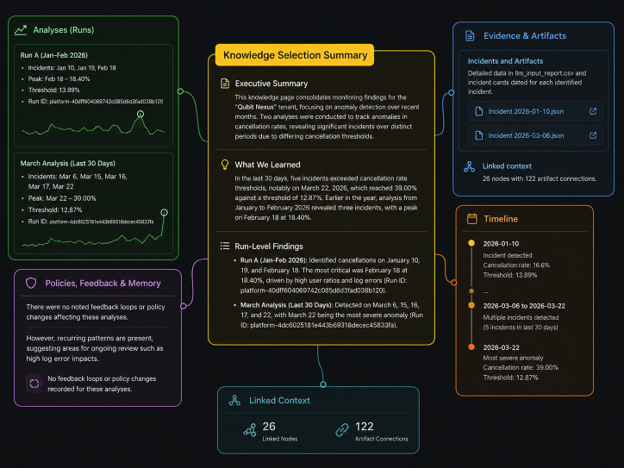
We built the AI Monitoring Agent to change that pattern. The goal was to move from reactive monitoring to a proactive, self-learning system — one that detects churn and performance anomalies in real time, explains their causes, and learns from every cycle.
In short, we wanted a monitoring system that could think like an analyst and act like a guardian, protecting customer experience and revenue before it’s too late.
How It Works: Under the Hood
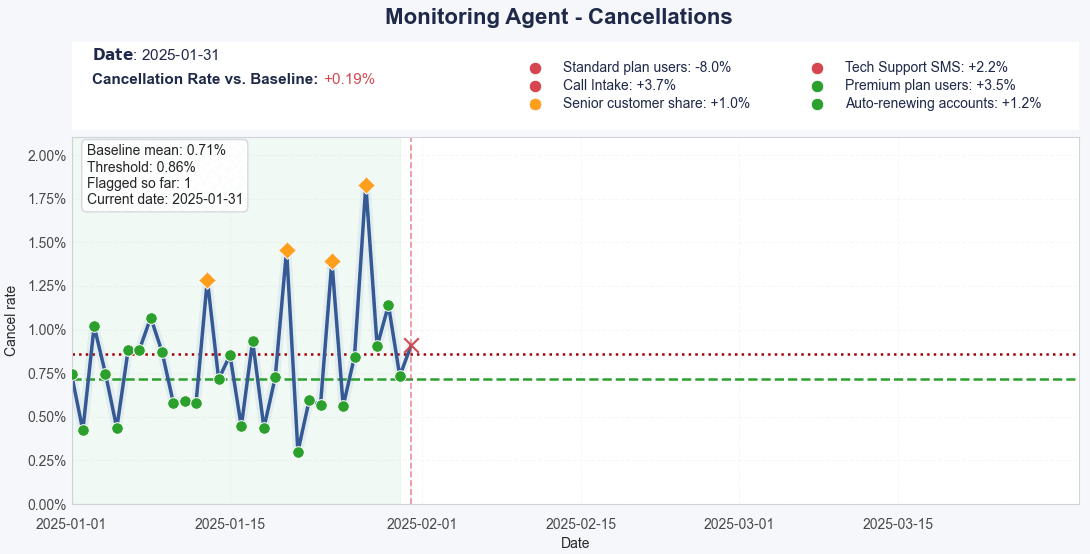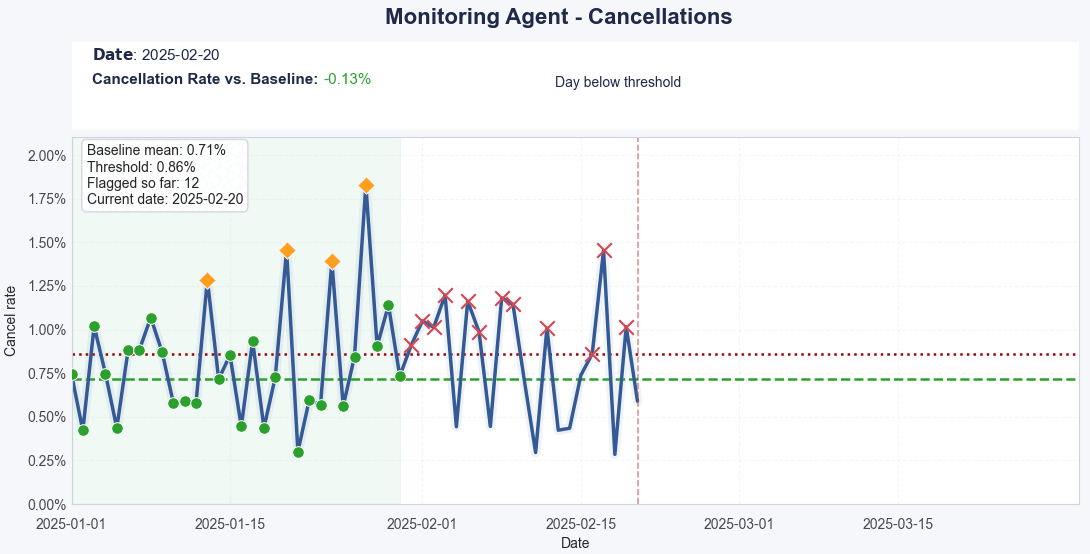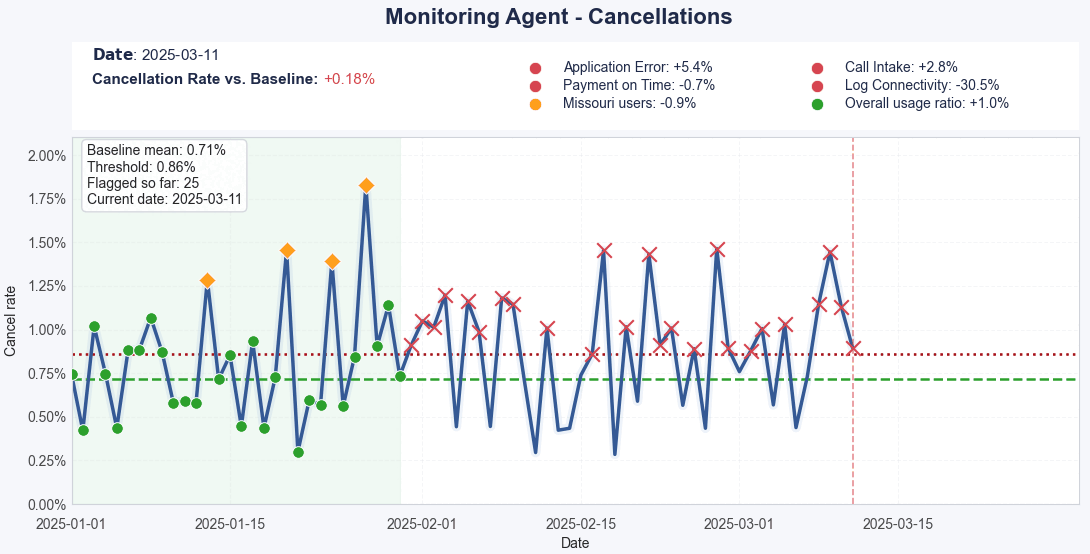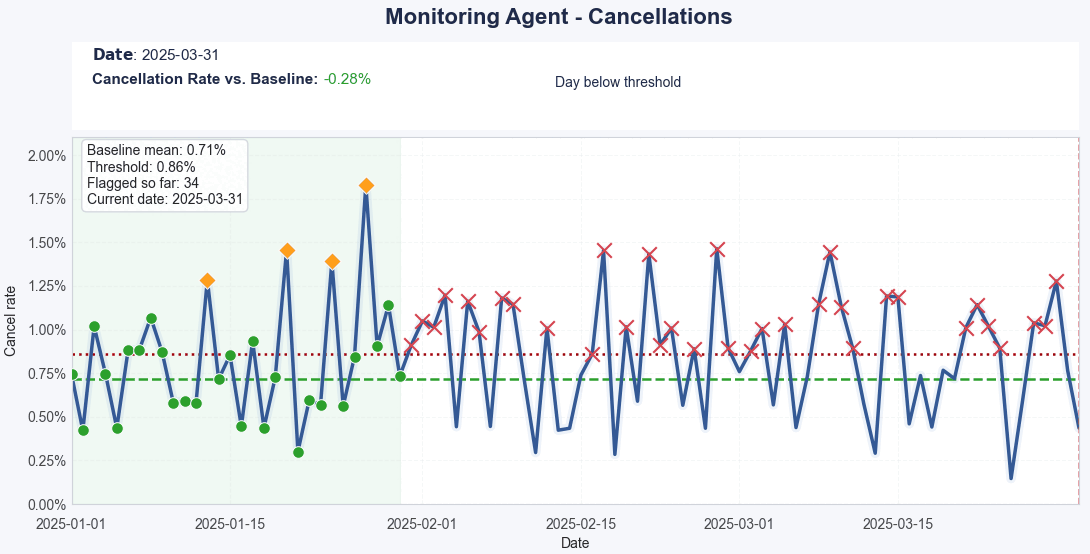
At its core, the AI Monitoring Agent runs a daily monitoring cycle. Each day, it collects operational and behavioral data, aggregates it into key metrics (like churn, conversion, or engagement), and compares these against a dynamic baseline.
This baseline is not static — it evolves with the business. Stable days are included in the reference; unstable or anomalous ones are excluded to keep the benchmark accurate and representative.
Each new day is automatically classified as normal or flagged, based on whether it stays within expected ranges. When anomalies occur, the system triggers an escalation path, sending the event for autonomous investigation.
The Intelligence Layer
Here’s where the system gets smarter:
Learning Normal Behavior – Using historical modeling, the system learns what “normal” looks like for each metric, factoring in seasonality, growth, and customer behavior shifts.
Real-Time Detection – When it detects a deviation (e.g., a churn spike), it automatically classifies it and starts investigating.
Autonomous Diagnosis – The AI explores datasets, correlates variables, and identifies the likely drivers behind the anomaly.
Context-Aware Filtering – It uses business context (like releases, outages, or campaigns) to filter out false positives.
Self-Improving Feedback Loop – The findings are summarized into structured CSV outputs, which are then analyzed by a language model that synthesizes insights and suggests possible causes. The resulting explanations feed back into the system to continuously refine accuracy.
This creates a closed learning loop — where the Agent not only monitors but also understands and improves.
From Data to Decisions
The real advantage isn’t just detection — it’s acceleration.
Traditional analytics workflows rely on analysts to spot anomalies, dig into data, and interpret patterns. That process can take days. The AI Monitoring Agent compresses that into minutes, automatically surfacing:
What happened
Why it happened
How significant it is
Which teams should act
That speed fundamentally changes how businesses operate. Instead of waiting for monthly reviews, teams can act in real time — mitigating churn, optimizing campaigns, and stabilizing operations before the impact compounds.
Strategic Value
For leadership, this means more than operational efficiency. It means turning analytics into a competitive advantage.
The AI Monitoring Agent enables proactive management — empowering teams with actionable insights the moment they’re needed. It protects revenue, strengthens customer relationships, and builds organizational resilience.
As we continue to evolve the system, our north star is clear: a truly autonomous analytics layer — one that not only diagnoses issues but predicts and prevents them.
That’s the future we’re building: from dashboards to self-learning insights.