Automated extraction
OCR and NLP read applications, financial statements, underwriting notes, KYC files, contracts, and regulatory filings to extract key financial metrics.
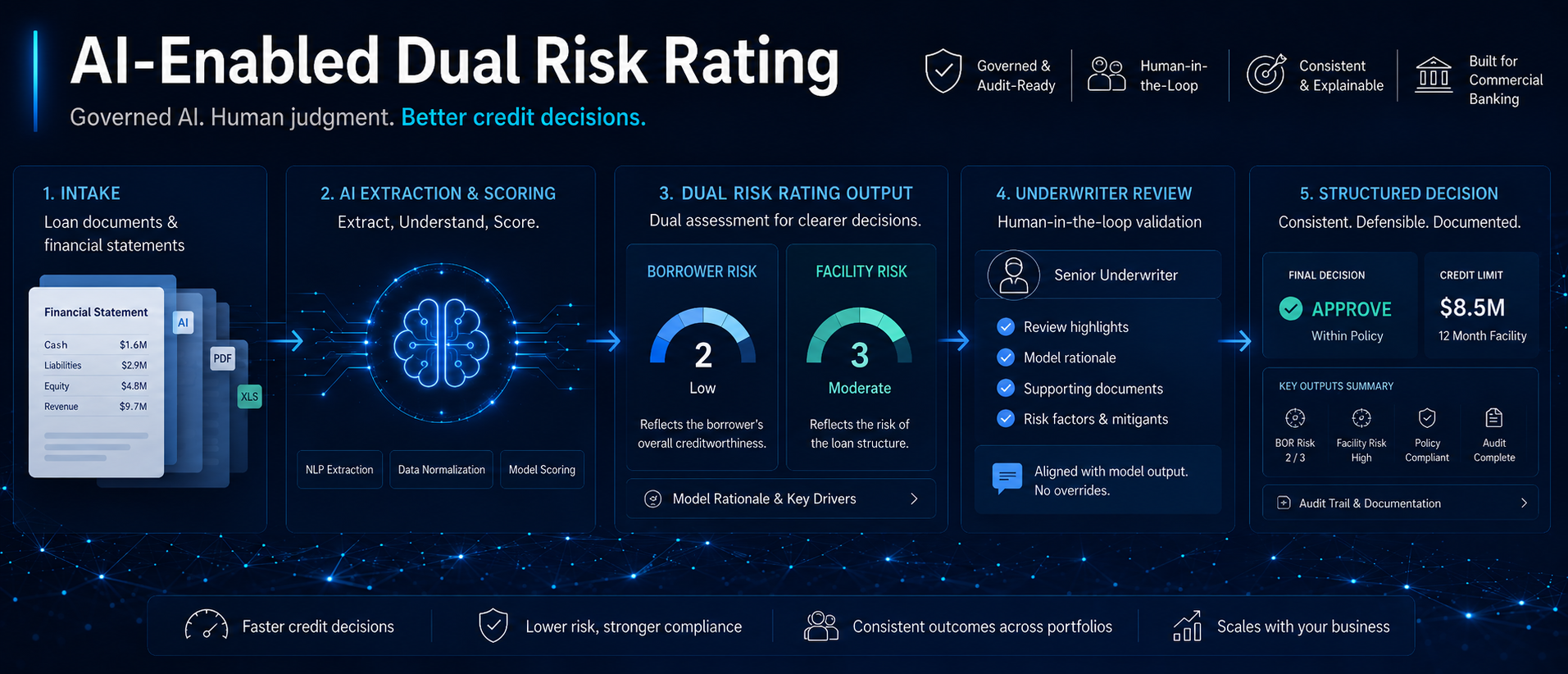
A dual risk rating workflow that gives underwriters a consistent, auditable quantitative baseline while keeping final loan approval authority with people. OCR, NLP, machine learning, and confidence routing improve speed and scale without removing human credit judgment.

More realized losses concentrated in the riskiest rating band during back-testing.
AI creates the quantitative baseline; underwriters retain final approval authority.
Read accuracy, confidence, policy, and eligibility checks prevent weak inputs from becoming ratings.
SmartBank assigns every commercial borrower an internal risk rating that drives approve/reject decisions and loan pricing. The legacy process relied heavily on individual underwriters manually interpreting financial statements, disclosures, and policy rules.
Applications could arrive through a call center, in person, or online. From there, underwriters entered application details into internal systems, reviewed financial statements by hand, converted key metrics into predefined bins, and applied policy weights before assigning a final internal rating on a 1-5 scale.
Defaults are rare in a healthy commercial book, often around 1%, so the most valuable risk signal is concentrated in a small subset of failed loans. That made the process especially sensitive to data quality, expert judgment, and consistent interpretation.

Applications arrive through in-person, call center, or online channels.
Underwriters key application data into internal systems by hand.
Financial statements and disclosures are read and interpreted manually.
Metrics are placed into predefined bins, weighted by policy, and converted into an internal rating.
Lower ratings are approved at different pricing levels; higher ratings are rejected.

OCR and NLP read applications, financial statements, underwriting notes, KYC files, contracts, and regulatory filings to extract key financial metrics.
A machine learning model predicts risk from extracted metrics and historical loan performance, then maps the output to the bank's 1-5 rating scale across obligor risk and facility risk.
Read accuracy, completeness, model confidence, and policy checks hold or route cases before weak inputs can silently become ratings.
Underwriters review the AI-generated rating, chat with the application and supporting documents, drill into sources, and apply a qualitative overlay where judgment requires it.
Low-risk, low-dollar loans can be auto-approved while high-risk, high-value, borderline, or low-confidence cases are escalated for human review.
Methodology, assumptions, performance, limitations, versioning, and monitoring are documented for model risk review and audit readiness.

The underwriter does not receive a black-box score. The review dashboard exposes the extracted values, source documents, page references, confidence levels, policy checks, and exception flags used to produce the rating.
The same idea supports the small-data problem in commercial lending: because default cases are rare, the system learns from curated, context-rich examples rather than depending only on volume. Each review and override becomes feedback for future extraction, scoring, monitoring, and retraining.

In back-testing against historical loan performance, model-derived ratings showed stronger risk separation than manual underwriter ratings. The riskiest model band captured roughly 10% more realized losses than the historical riskiest band.
The result is a faster, more consistent rating process that preserves sound credit judgment, regulatory compliance, and human accountability.